最近在做 AI Agent 项目,一下子接触到了很多新的专业术语。很多术语我都停留在“大概知道是干嘛的”这个层次,真要让我解释清楚它是怎么工作的,我其实说不明白。
所以我准备 各个击破。每个重要的概念,做一个 toy project,自己跑一遍整个流程。
RAG 是我的第一个学习目标。RAG 听过很多遍了,有些是同事说起的,有些是在 B 站看到的,甚至在抖音的评论区也看过,可见这个技术的火热程度。学习之前,我对 RAG 的理解停留在“做知识库”这个层面。
所以这篇文章主要记录两件事:
- 我是怎么一步步把 RAG 的主流程搞明白的
- 我是怎么基于自己的博客,做出一个最小可运行的 toy RAG 项目的
项目地址先放这:
什么是 RAG,我们为什么需要 RAG
RAG 全称是 Retrieval-Augmented Generation,一般翻译成“检索增强生成”。
如果只看名字,它有点抽象。但换成更直白的话,其实就是:
先去外部知识库里找资料,再把找到的资料和用户问题一起交给大模型,让它基于这些资料回答。
我一开始对它的理解是:
“把大的知识库分片,然后挑出一部分发给 LLM,而不是把整个知识库都发给 LLM。”
这个理解不能说错,但还不够完整,因为它只解释了“RAG 大概有用”,没有解释“为什么需要它”。
RAG 存在的必要性,主要来自下面几个现实问题。
1. 大模型并不天然知道你的私有知识
大模型参数里有很多通用知识,但它不知道你的公司文档、你的个人博客、你的产品手册、你的代码仓库。
这些内容如果不额外接进来,模型就只能靠猜。
2. 把整个知识库都塞进 Prompt 是不现实的
最朴素的想法是:既然模型不知道,那我把所有资料一股脑贴进去不就行了?
理论上可以,实际上通常不行。因为知识库一大,会立刻遇到几个问题:
- 上下文窗口有限:模型能吃进去的 token 是有限的
- 成本高:每次都把大量无关资料送进去,token 消耗会很夸张
- 噪音大:资料太多时,真正有用的信息反而会被淹没
- 延迟高:输入越长,调用越慢
所以问题不只是“能不能发给模型”,而是“能不能只发最相关的那一小部分”。
3. 纯靠大模型回答,容易幻觉
如果模型没有拿到足够的外部依据,它往往也不会老老实实说“我不知道”,而是根据自己见过的相似模式给你补一个看起来很像真的答案。
RAG 的价值就在于:
它尽量先把资料找出来,再要求模型基于资料回答。这样回答的依据更明确,调试时也能知道它到底是“没检索到”还是“看到了但总结错了”。
4. 知识变化很快,不适合全靠训练更新
像博客、文档、FAQ、产品说明这类内容,变化是很频繁的。
如果每次内容更新都去重新训练模型,成本太高,也不现实。
RAG 的思路是把知识放在模型外部:
知识更新了,只要重新做索引,不用重新训练模型。
所以我现在会把 RAG 理解成:
它不是一个新模型,而是一种系统设计:把“检索外部知识”和“基于知识生成答案”串起来。
RAG 的执行过程是什么样的
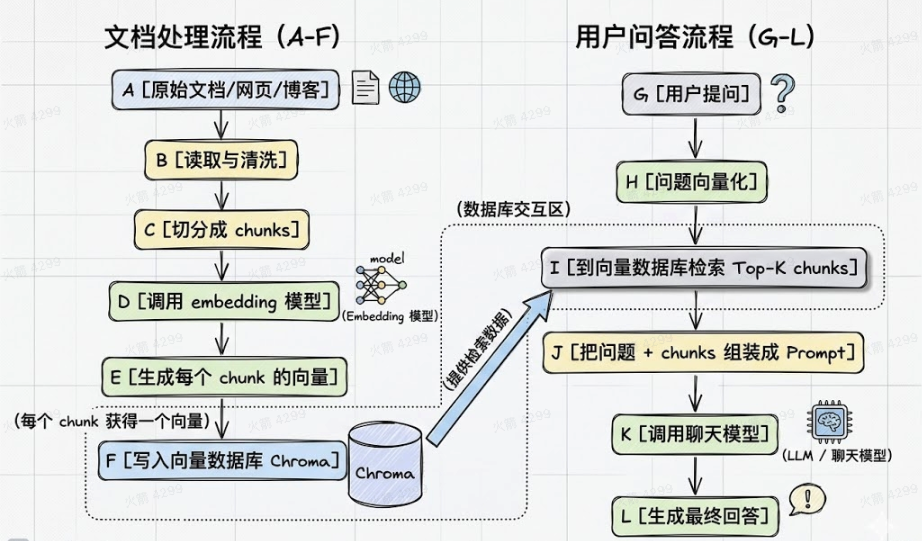
我后来真正开始理解 RAG,是因为把它拆成了两个阶段看:
- ingest 阶段:建索引
- chat 阶段:问答
如果用一句话概括:
- ingest 阶段负责“把知识库准备好”
- chat 阶段负责“拿用户问题去查,再基于结果回答”
可以先看整个主流程:
toy project
为了把这套流程真正走一遍,我基于自己的博客做了一个最小可运行的 RAG 项目:
- 项目地址:https://github.com/huojian-jan/blog-rag-lab
- 数据源是
data/目录里的博客链接清单 - 程序会抓取网页正文,切成 chunk,做 embedding,然后写入本地 Chroma
- 问答阶段通过命令行提问,先检索相关片段,再交给模型组织答案
- 输出结果时还会把参考片段、来源链接和相似度一起打印出来,方便调试
核心就是 Python、LlamaIndex、Chroma 和 OpenAI 兼容接口。它没有做 Web UI,也没有上复杂的检索策略,容易看清楚 ingest 和 chat 这两条链路到底分别在做什么。
小结
把这条链路拆开以后,我对 RAG 的理解就清楚多了。它其实就是把几件事按顺序串起来:
- ingest 阶段把外部知识整理成可检索的形式
- chat 阶段根据用户问题召回最相关的内容
- 最后再由模型基于这些内容组织答案
切 chunk、做 embedding、文档清洗、检索质量和 prompt 组织…,每个阶段都有很多值得深入研究的地方,但是因为我的目的不是发论文,只是在广度上补充我缺失的领域知识,暂时学习到这个层次就够了。